本帖最后由 piaolin 于 2015-10-30 14:02 編輯
通常認為,C語言之所以強大,以及其自由性,很大部分體現在其靈活的指針運用上,甚至認為指針是C語言的靈魂。這里說通常,是廣義上的,因為隨著編程語言的發展,指針也飽受爭議,并不是所有人都承認指針的“強大”和“優點”。在單片機領域,指針同樣有著應用,本章節針對Keil C-51環境下的指針意義做簡要分析。
1 指針與變量
指針是一個變量,它與其他變量一樣,都是RAM中的一個區域,且都可以被賦值,如程序①所示。
#include "REG52.H"
unsigned int j;
unsigned char *p;
void main()
{
while(1)
{
j=0xabcd;
p=0xaa;
}
}
在Debug Session模式下,將鼠標指針移到到變量“j”“p”位置,可以顯示變量的物理地址,如圖1-1、1-2所示。
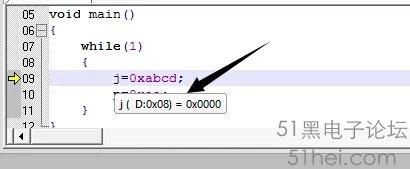
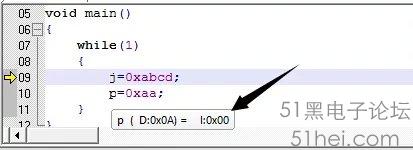
圖中箭頭所指處即為變量在RAM中的“首地址”,為什么是“首地址”呢?變量根據類型可分為8位(單字節)、16位(雙字節),程序中變量“j”是無符號整型,所占物理空間應為2字節,而在8位單片機中,RAM的一個存儲單元大小是8位,即1字節,因此需2個存儲單元才滿足變量“j”長度。所以實際上變量“j”的物理地址為“08H”“09H”。同理,“p(D:0x0A)”即變量“p”的首地址為“0AH”。
下面通過單步執行程序來觀察RAM內的數據變化,打開兩個Memory Windows窗口,在Keil軟件下方顯示為Memory1和Memory2,在兩個窗口中,分別做如圖2-1、2-2所示的設置。
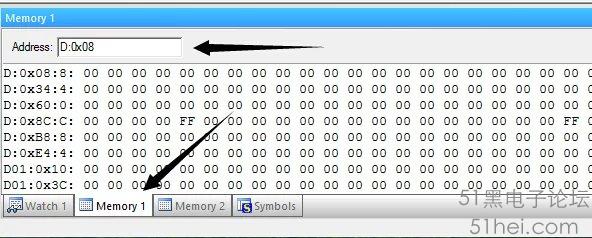

兩個Address填寫的內容分別是:D:0x08、D:0x0A,即變量“j”和變量“p”的首地址,輸入后回車,便可監視RAM中該地址下的數據。設置好后,準備調試。
在Debug Session模式中,箭頭所指處即為即將執行的語句,單擊“Step”功能按鈕(或按F11鍵),讓程序運行,如圖3所示。
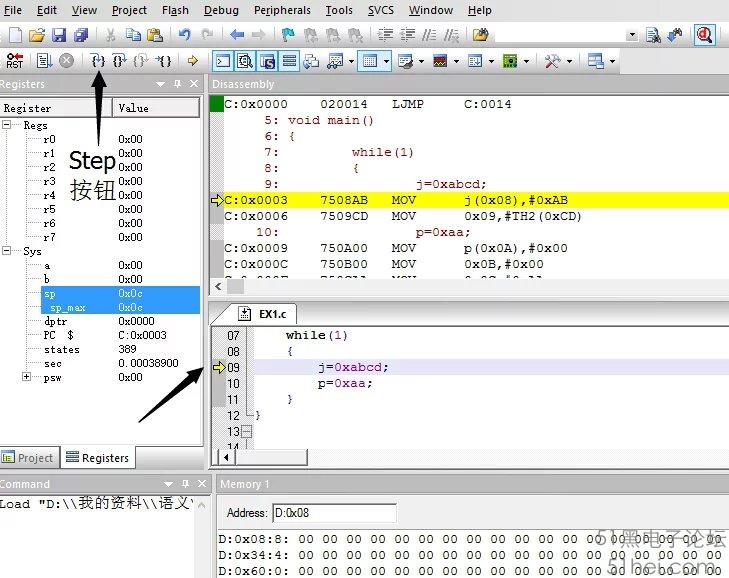
第一次單擊“Step”按鈕后,Memory1窗口內數據如圖4所示。
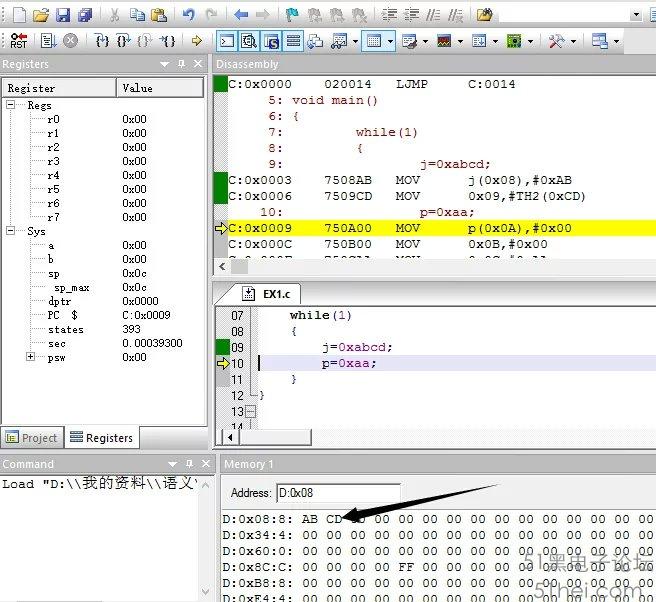
由調試結果可知,08H數據由00H變為ABH,09H數據由00H變為CDH,出現這種變化是因為執行了語句j=0xabcd;08H為變量“j”高八位,存儲“AB”,09H為變量“j”低八位,存儲“CD”。
第二次單擊“Step”按鈕,執行語句:p=0xaa;此時需觀察Memory2窗口內數據,如圖5所示。

由調試結果可知,0CH處值由00變為“AAH”,程序相吻合。這里需要注意,在Keil C-51編譯環境下,指針變量,不管長度是單字節或是雙字節,指針變量所占字節數為3字節。故此處“AAH”不是存儲在0AH而存儲在0CH(0A+2)地址中。
綜上所述,指針實際上是變量,都是映射到RAM中的一段存儲空間,區別是,指針占用3字節,而其他變量可根據需要設定其所占RAM是1字節(char)、2字節(int)、4字節(long)。
2 指針作用
指針的作用是什么呢?先來看下面的程序:
程序②
#include "REG52.H"
unsigned chartab1[8]={0x01,0x02,0x03,0x04,0x05,0x06,0x07,0x08};
unsigned char codetab2[8]={0x10,0x20,0x30,0x40,0x50,0x60,0x70,0x80};
unsigned char N1,N2;
void main()
{
N1=tab1[0];
N2=tab2[0];
}
顯然,程序執行的結果是N1=0x01,N2=0x10。這里都是講數組內的數據賦值給變量,但存在區別,tab1數組使用的是單片機RAM空間,而tab2數組使用的是單片機程序存儲區(ROM)空間。盡管使用C語言為變量賦值時語句相同,但編譯結果并不相同,此程序編譯后的結果如圖6所示。
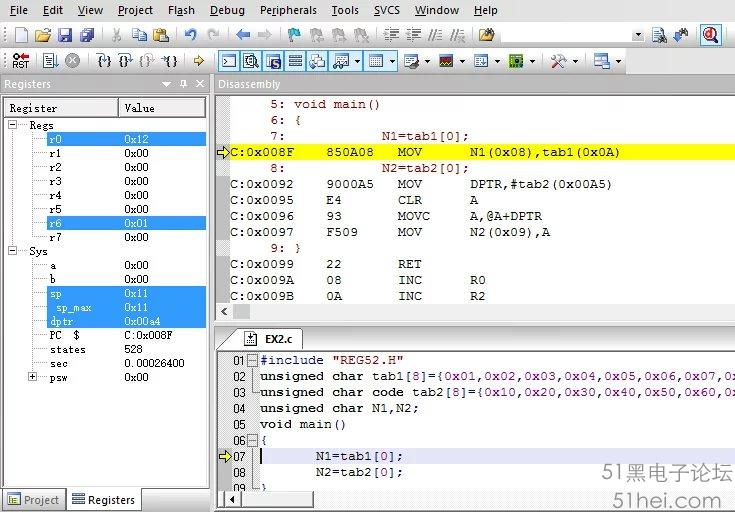
由編譯結果可知,N1=tab1[0]語句實際上是直接尋址,而N2=tab2[0]是寄存器變址尋址。不管是何種尋址方式,都是將一個物理地址內的數據取出來使用:tab1數組中,tab[0]對應的RAM地址是0x0A,tab[1]對應的RAM地址是0x0B……以此類推;tab2數組中,tab[0]對應的ROM地址是0x00A5,tab[1]對應的ROM地址是0x00A6……以此類推。不管這些數組或變量所在的RAM或ROM地址如何,用戶最終需要的是數組或變量的數據,而指針,就是通過變量或數組的物理地址訪問數據,也就是說,通過指針,同樣可以訪問數組或變量數據。現將程序②做出調整,得到程序③如下:
#include "REG52.H"
unsigned chartab1[8]={0x01,0x02,0x03,0x04,0x05,0x06,0x07,0x08};
unsigned char code tab2[8]={0x10,0x20,0x30,0x40,0x50,0x60,0x70,0x80};
unsigned char N1,N2;
unsigned char *p;
void main()
{
unsignedchar i;
p=tab1;
for(i=0;i<8;i++,p++)
N1=*p;
p=tab2;
for(i=0;i<8;i++,p++)
N2=*p;
}
程序執行結果:tab1數組內的8個數值依次被賦值給N1;tab2數組內的8個數值依次被賦值給N2;
程序③執行Debug Session功能后,打Watch Windows窗口,在Watch1窗口下添加需要監視的變量,此處為“p”和“N1”,如圖7所示。
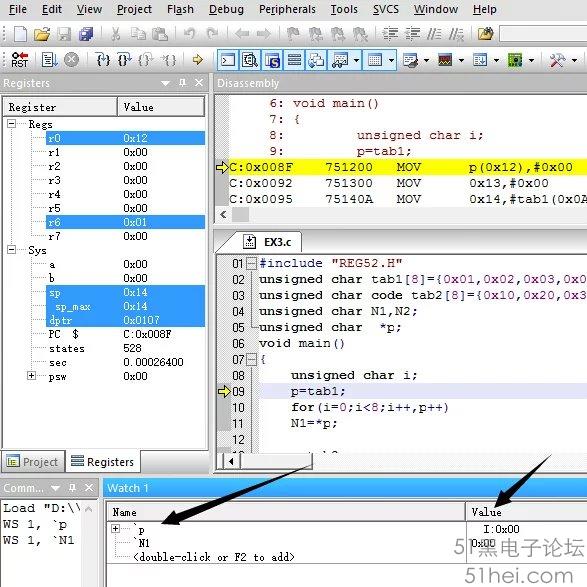
Value為當前變量數值,程序為運行前,p值為0x00,單擊Step按鍵功能后,執行p=tab1;p值變為0x0A,如圖8所示。
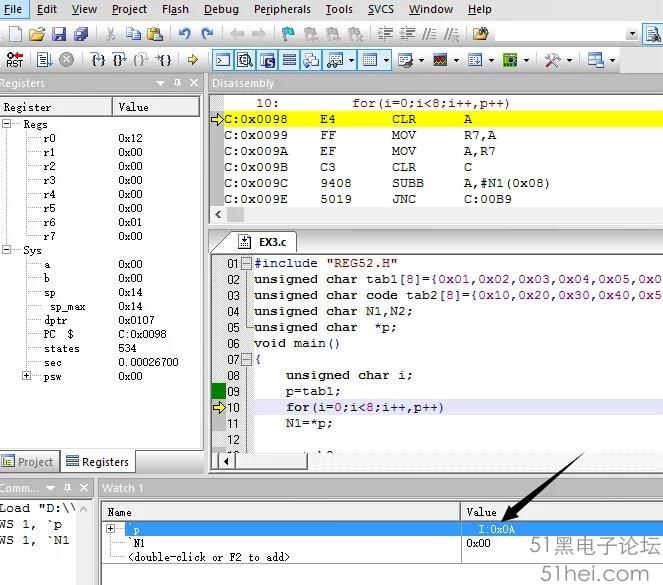
0x0A是什么值呢?將鼠標移至tab1數組位置,可顯示出數組所在的物理地址,0x0A就是數組tab1的首地址,如圖9所示。
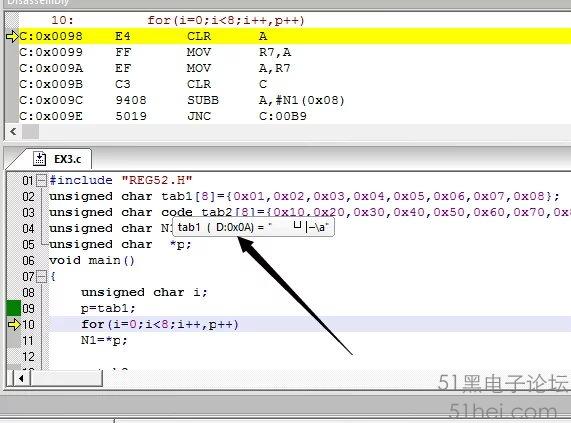
p=tab1就是將tab1數組的首地址賦值給變量p,執行p++即地址值加1;*p則是此物理地址內的具體數據,因此for循環中,N1=*p是依次將tab1數組中的數據賦值給變量N1。由此可見,指針是作為一個變量,指向某一個地址。
那么指針到底是如何將某個地址內的數據“拿”出來的?下面通過N1=*p語句做演示說明,N1=*p編譯后的匯編代碼如圖10所示。
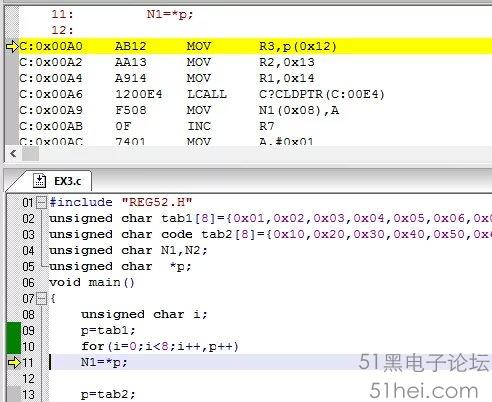
C:0x00A0至C:0x00A9的匯編代碼即是C程序中的N1=*p。程序先將變量p的值賦值給R3、R2、R1三個通用寄存器,程序為:
MOV R3,p(0x12)
MOV R2,0x13
MOV R1,0x14
然后調用了一個子函數:LCALL C?CLDPTR(C:00E4),而C程序中,未定義或使用任何子函數,那么這個子函數是哪里來的?作用是什么?根據標號C:00E4可找到該子函數,程序代碼如下:
C:0x00E4 BB0106 CJNE R3,#0x01,C:00ED
C:0x00E7 8982 MOV DPL(0x82),R1
C:0x00E9 8A83 MOV DPH(0x83),R2
C:0x00EB E0 MOVX A,@DPTR
C:0x00EC 22 RET
C:0x00ED 5002 JNC C:00F1
C:0x00EF E7 MOV A,@R1
C:0x00F0 22 RET
C:0x00F1 BBFE02 CJNE R3,#0xFE,C:00F6
C:0x00F4 E3 MOVX A,@R1
C:0x00F5 22 RET
C:0x00F6 8982 MOV DPL(0x82),R1
C:0x00F8 8A83 MOV DPH(0x83),R2
C:0x00FA E4 CLR A
C:0x00FB 93 MOVC A,@A+DPTR
C:0x00FC 22 RET
此程序功能是:先用R3寄存器的值與0x01比較,當R3的值大于0x01時,再和0xFE做比較,比較的結果有如下情況:
(1)R3的值等于0x01時,執行如下程序:
C:0x00E7 8982 MOV DPL(0x82),R1
C:0x00E9 8A83 MOV DPH(0x83),R2
C:0x00EB E0 MOVX A,@DPTR
C:0x00EC 22 RET
程序功能:讀取擴展RAM內的數據并賦值給A,尋址范圍0~65535。當數組用xdata定義時,會跳轉到此處。
(2)R3的值小于0x01即等于0x00時,執行如下程序:
C:0x00EF E7 MOV A,@R1
C:0x00F0 22 RET
程序功能:讀取單片機內部256字節RAM內的數據并賦值給A,尋址范圍0~255。當數組用data或idata定義時,會跳轉到此處。如執行N1=*p語句時,即跳轉到自處,讀取內部RAM地址內的數據。
(3)R3的值不等于0x00或0x01時,通過JNC指令跳轉到C:0x00F1處,開始與0xFE做比較。R3的值等于0xFE時,執行如下程序:
C:0x00F4 E3 MOVX A,@R1
C:0x00F5 22 RET
程序功能:讀取單片機片外RAM內的數據并賦值給A,尋址范圍0~255。當數組用pdata定義時,會跳轉到此處。通常8051單片機不使用pdata定義變量或數組。
(4)R3的值不等于0xFE時,即R3的值等于0xFF時,跳轉到C:0x00F6處執行如下程序:
C:0x00F6 8982 MOV DPL(0x82),R1
C:0x00F8 8A83 MOV DPH(0x83),R2
C:0x00FA E4 CLR A
C:0x00FB 93 MOVC A,@A+DPTR
C:0x00FC 22 RET
程序功能:讀取單片機內部ROM內的數據并賦值給A,尋址范圍0~65535。當數組用code定義時,如程序③中,tab2數組用code定義,執行p=tab2后,R3的值被賦值為0xFF,再執行N2=*p語句時,即跳轉到自處,讀取內部ROM地址內的數據。
由此可見,子函數“C?CLDPTR”的作用是,根據數據所在存儲空間,用不同的尋址方式讀取某地址下的數據。R3用于確定尋址方式,R3的值與對應的尋址方式對應關系為:
1、R3值等于0x00時,片內RAM間接尋址;此時數據用dataidata定義。
2、R3值等于0x01時,片外RAM(擴展RAM)間接尋址;此時數據用xdata定義。
3、R3值等于0xFE時,片外RAM(擴展RAM)低246字節間接尋址;此時數據用pdata定義
4、R3值等于0xFF時,從存儲存儲器(ROM)進行變址尋址;此時數據用code定義。
3、指針結構
R3、R2、R1的值是RAM中0x12、0x13、0x14地址內的值,即變量p映射的RAM地址。而而8位單片機中,不管是何種尋址方式,最大尋址范圍是2字節長度(0~65535),為什么指針*p卻占用了3字節RAM空間呢?下面通過程序④說明。
程序④:
#include "REG52.H"
unsigned char tab1[8];
unsigned char idata tab2[8];
unsigned char xdata tab3[8];
unsigned char pdata tab4[8];
unsigned char codetab5[8]={0x10,0x20,0x30,0x40,0x50,0x60,0x70,0x80};
unsigned char *p;
void main()
{
p=tab1;
p=tab2;
p=tab3;
p=tab4;
p=tab5;
}
在Debug Session模式下可知,程序中數組與變量所映射的物理地址為及物理存儲區分別為:
tab1 : 0x08~0x0F 單片機內部RAM
tab2: 0x03~0x1A 單片機內部RAM(idata)
tab3: 0x08~0x0F 單片機擴展RAM(xdata)
tab4: 0x00~0x08 單片機擴展RAM低256字節(pdata)
tab5: 0x0003D~0x0044 單片機程序存儲區(code)
p: 0x10~0x12 單片機內部RAM
注:擴展RAM可以在物理上可以分為片內或片外,如STC15系列增強型單片機的擴展RAM與單片機是封裝在一起的,即片內擴展RAM;傳統8051單片機沒有片內擴展RAM,需連接外部RAM芯片,此為片外擴展RAM。
在Memory Windows窗口下,監視變量p映射的RAM地址:0x10~0x12的數值變化,如圖11所示。
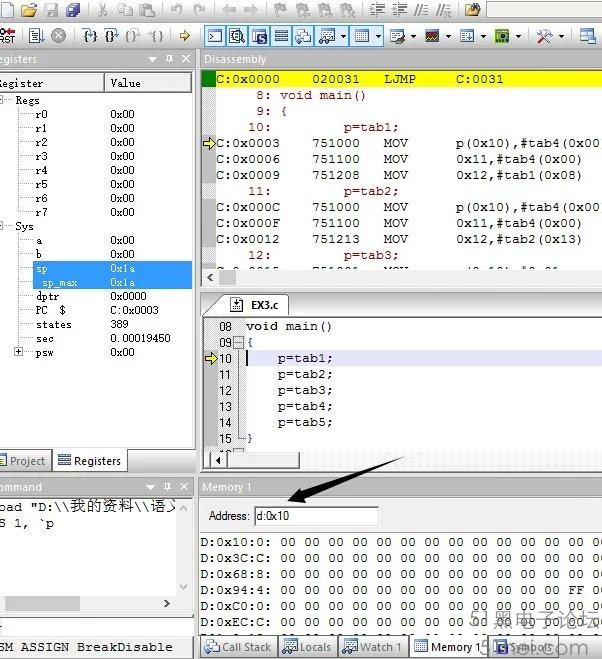
通過“Step”功能按鈕執行住函數中的5調語句,可觀察到0x10~0x12寄存器的數據變化:
執行p=tab1后,0x10、0x11、0x12:0x00、0x00、0x08
執行p=tab2后,0x10、0x11、0x12:0x00、0x00、0x13
執行p=tab3后,0x10、0x11、0x12:0x01、0x00、0x08
執行p=tab4后,0x10、0x11、0x12:0xFE、0x00、0x00
執行p=tab5后,0x10、0x11、0x12:0xFF、0x00、0x3D
由此可知,0x10的賦值取決于p指向的物理存儲區,0x11、0x12的值是數據存儲區的地址。指針所映射的首地址,會根據指向的物理存儲區被編譯器賦不同的值:0x00,0x01,0xFE,0xFF。這與程序③得到的結論一致,程序③中,寄存器R3、R2、R1對應值實際上就是指針所映射的3字寄存器數值。
結合程序③編譯分析,當需要引用某物理地址內數據時,會調用“C?CLDPTR”函數,函數功能就是根據這些賦值確定使用何種尋址方式引用數據。而這一過程包括“C?CLDPTR”函數都是編譯器自動完成的。
在匯編語言中,R1寄存器可以用于間接尋址,如:MOV A,@R1。不能寫為MOV A,@12H。因此在程序③中,將變量p對應的3字節數據賦值給R3、R2、R1。
綜上所述,Keil C-51編譯環境下,指針是一個占3字節的特殊變量,編譯器編譯程序時,自動生成判斷尋址方式的子函數,并根據根據目標數據所在的物理存儲區不同,為指針首字節賦值,根據賦值的不同,進行不同方式的尋址;指針的后2字節,用于存放引用的地址。
調試訓練:
下面的程序編譯器會怎樣編譯?與程序③有何不同?請根據程序③和程序④的分析方式分析程序⑤的執行結果。
程序⑤
#include "REG52.H"
unsigned char tab1[8];
unsigned char codetab2[8]={0xff,0xff,0xff,0xff,0xff,0xff,0xff,0xff};
unsigned char *p;
void main()
{
unsignedchar i;
p=tab1;
for(i=0;i<8;i++,p++)
*p=i;
p=tab2;
for(i=0;i<8;i++,p++)
*p=i;
}
思考:下列語句中:
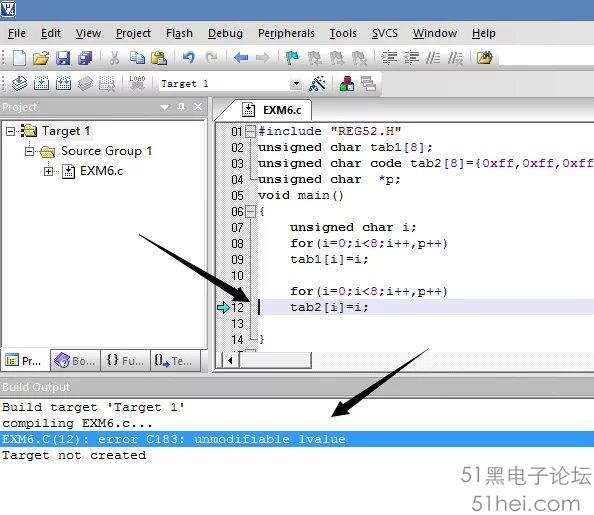
p=tab2; for(i=0;i<8;i++,p++) *p=i; 執行完for循環后,tab2數組內的值會改變嗎?為什么? 4、指針意義 在匯編編程中,由于單片機數據存放的物理存儲區不同,導致有不同的尋址方式,用戶進行必須根據這一規律設計程序。而在C語言中,不管目標數據所在的物理存儲區如何,指針都可指向該地址,并自動編譯尋址方式。 但指針并不是萬能的,如程序⑤中: p=tab2; for(i=0;i<8;i++,p++) *p=i; 這些語句編譯時并不會報錯,但卻不能實現功能,因為tab2數組是定義在程序存儲器(ROM)的常量數組,ROM內的數據更改是不能通過這種方式實現的。因此,當用戶不明確單片機的物理存儲區特性時,使用指針會容易出錯。先將程序⑤中的主函數語句做如下修改,得到程序⑥: #include"REG52.H" unsignedchar tab1[8]; unsignedchar code tab2[8]={0xff,0xff,0xff,0xff,0xff,0xff,0xff,0xff}; unsignedchar *p; voidmain() { unsigned char i; for(i=0;i<8;i++,p++) tab1[ i]=i; for(i=0;i<8;i++,p++) tab2[ i]=i; } 單獨看第一個for循環,可實現與程序⑤一樣的效果,即tab1數組內被賦值為:0,1,2,3,4,5,6,7。 第二個for循環從語句上可認為是與程序⑤功能相同,但實際上,不管是程序⑤還是程序⑥,都不能實現對tab2數組的賦值。但在程序⑥中,編譯器會提示錯誤,如圖12所示。 因此,指針的使用不當,不僅會帶來程序運行結果的不正確,同時也難以發現這些錯誤。 對比程序⑤和程序⑥中的兩段程序:
p=tab1; for(i=0;i<8;i++,p++) for(i=0;i<8;i++,p++) tab1[ i]=i; *p=i;
它們執行的結果是一樣的,那么哪種更好呢?對于初學者來說,顯然是后者,因為后者更易于理解程序含義,而前者必須要理解指針在此處的作用;那么對于有經驗的程序員呢?也是后者,因為程序執行效率上,后者也要大于前者,因為程序⑤在編譯過程中,編譯器始終會生成一個子函數用于確定尋址方式,再賦值;程序⑥則是直接確定了尋址方式執并行進行賦值。盡管執行效率的降低在接受范圍內,但對于一個簡單、明了的功能來說,用簡單的方式實現要比復雜方式合理。
設計者在程序中使用指針的目的往往是讓程序具有可移植性,但8051單片機的功能是有限的,它實現的功能相對固化,如時間顯示、數據采集等等,這些功能確定后,幾乎不會做出更改,基于此特點,8051單片機的代碼代碼量都不長。因此即便是不同構架的單片機程序互相移植,代碼的修改并不復雜,移植過程中,也幾乎都是針對不同構架單片機的I/O工作方式不同、指令周期不同做常規修改;或是關鍵字的修改。因此合理的設計單片機程序,盡可能的提高程序的效率、穩定性、可閱讀性才是程序設計的核心主旨。指針在8051單片機中固然可以使用,但并不能說明指針的使用就一定是高效、準確、易于他人理解。
|



 [復制鏈接]
[復制鏈接]




 QQ好友和群
QQ好友和群 QQ空間
QQ空間 騰訊微博
騰訊微博 騰訊朋友
騰訊朋友 收藏
收藏 淘帖
淘帖 頂
頂 踩
踩

