標題: 微軟研究院人工智能首席科學家鄧力:人工智能的成功在于將多種理論方法整合成一個... [打印本頁]
作者: 51黑專家 時間: 2016-4-21 22:01
標題: 微軟研究院人工智能首席科學家鄧力:人工智能的成功在于將多種理論方法整合成一個...
機器之心原創
作者:趙云峰
鄧力,微軟研究院人工智能首席科學家,美國 IEEE 電氣和電子工程師協會院士。2015年,鄧力憑借在深度學習與自動語音識別方向做出的杰出貢獻,榮獲 IEEE 技術成就獎。鄧力首次提出并解決將深度神經網絡應用到大規模語言識別中,這一實踐顯著提高了機器對語音的識別率,極大推動了人機交互領域的發展與進步。
在阿爾法公社舉辦的「AI 領域跨越技術/產業/投資」及他在 IEEE-ICASSP 得獎之后的聚會上,機器之心有幸對鄧力研究員進行了一次深度專訪。鄧力介紹了自己和微軟研究院在做的關于人工智能的數項研究,回顧了自己在人工智能和語音識別領域的研究歷程,并深入分析了人工智能領域的研究現狀和未來發展, 針對無監督學習等人工智能難題提出了自己的研究思路和解決方法。相信鄧力的精彩分享將會給人工智能從業者帶來巨大收獲,其對人工智能的深入思考和研究理念也會給大家帶來寶貴的靈感和啟發。
 微軟研究院人工智能首席科學家鄧力
微軟研究院人工智能首席科學家鄧力
一、目前所做研究:人工智能算法、大規模商業應用以及各類人工智能方法的整合
很多實際問題不是非黑即白的,而是有很多中間狀態,我們在做一些比較大型的研究,將很多層神經網絡(包括時空上聯合的深層)與其他方法結合起來去應對這些不確定性。
機器之心:您能否介紹一下目前在微軟研究院做的人工智能方面的研究,您在語音識別領域獲得了巨大成功,除此之外還在做其他方面的研究嗎?
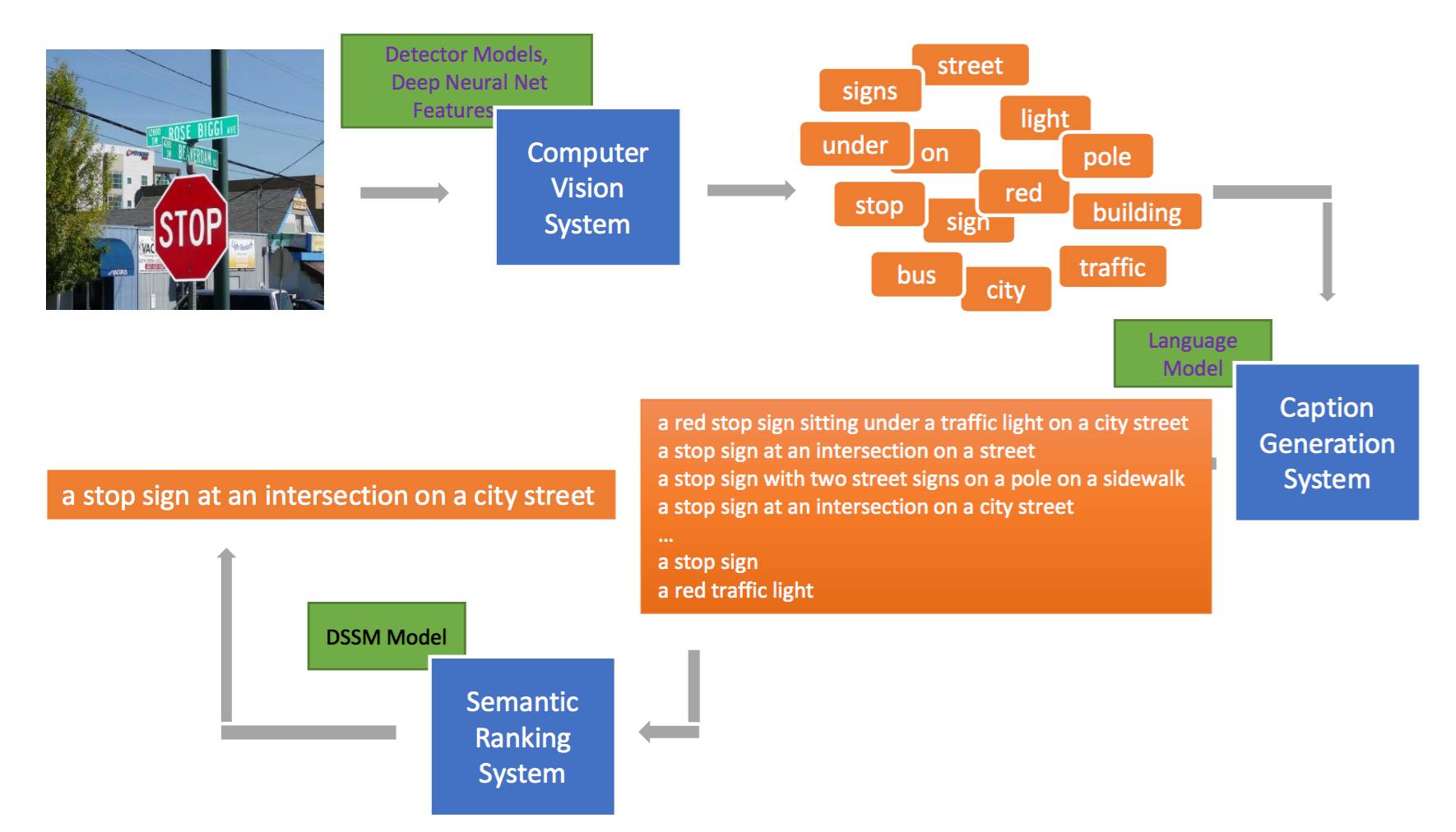
鄧力:總體來說,人工智能的各項研究我和我在研究院的團隊都在做。首先,語音識別和語言模型我做了很多年,圖像描述(Image Captioning)和有關多媒態近年來也在深入研究。 圖像描述就是給出一個圖像,機器可以寫出語法標準的句子來描述它,而且相當準。我的一支團隊去年用了一個類似于「圖靈測試」的方法進行測試,結果有32%的情況大家分不出哪些是機器自動寫的,谷歌同類系統的結果是31%,和我們差不多,人類是67%,這個技術在若干年后可能會達到人類水平。
微軟研究院的「圖像描述(Image Captioning)」,來源:鄧力在 IEEE-ICASSP 演講用的 PPT 和微軟美國研究院 CVPR-2015 論文「From Captions to Visual Concepts and Back」。
其次,我們現在做算法方面的研究比較多,包括語音識別和自然語言理解算法、增強學習算法等,以及如何將增強學習和其他機器學習方法整合在一起;如何將生成性深度學習和無監督學習進行融合, 等等。
第三是涉及人工智能在商業方面大規模實際應用。我們在研究具體問題要用什么樣的深度學習和人工智能方法來解決并怎樣采用最有效的方式。
而最重要的研究方向,是如何將大數據、深度學習以及人工智能各種方法整合在一起,使得機器學習和人工智能更加有效,而且對數據的要求也不能大到現實應用場景提供不了的地步。
總之,不管是方法研究還是應用研究,我們都是在做一些比較大型的和前沿性的研究,比如如何將很多層神經網絡與其他方法結合起來去應對解析性(explanability)以及應對各種不確定性(uncertinty),因為很多實際問題不是非黑即白的,而是有很多中間狀態,如何將這種概念與神經網絡結合起來,人工智能在這方面的研究還做的比較少。但現實世界中其實有很多的不穩定性和不確定性,如何在這種不確定的情況下做出最優決策?這就需要將深度學習其他方法整合在一起,然后才能做出適合真實世界的各類人工智能應用,包括語音、圖像、自然語言、翻譯,商業數據分析和 insight distillation 等。
機器之心:長短時記憶模型(LSTM)在研究中是否發揮了很大作用?
鄧力:是的,我們是在使用這個方法,但我認為目前的長短時記憶模型還不夠,它實際上還是個短時模型,用比較簡單和非嚴謹的方法把「短時」(short term)慢慢加長,但加長一段時間之后通常不夠有效,所以還需要其他更嚴謹的方法,包括記憶網絡(Memory Network),神經圖靈機(Neural Turing Machine)等。這些都是很有效的方法,我們目前也在研究比這些更進一步的方法。
機器之心:您平時會思考一些人工智能哲學方面的問題嗎?比如說機器意識之類的。
鄧力:我覺得機器意識離我們太遠了。我與其想那些,還不如多花些時間在深度學習算法和架構研究上,剛剛提到的無監督深度學習就值得我花大量時間去研究了。
二、個人的人工智能研究歷程以及與 Geoffrey Hinton 的合作
這是當時我和 Hinton 合作研究的一部分內容,把隱馬爾科夫模型和深度神經網絡結合起來,并取得了比較好的初步表現。
機器之心:您本科是學神經科學,后來是如何進入到人工智能領域的?能否介紹一下您和 Geoffrey Hinton 合作過程嗎?
鄧力:我在中科大本科學習神經科學和物理學,后來到美國研究聽覺神經系統與其計算模型。1985 年底還在做博士論文的時候,我用物理模型和神經模型來做聽覺模擬,但當時的神經網絡算的太慢。當時我也嘗試過把生物模型的特征提取出來丟到隱馬爾科夫模型里,結果很不理想,因為它們不是成熟的能夠相匹配的系統。后來我發現純統計方法更有用,從 80 年代中末期到深度學習出來之前,我做了很多研究,包括計算人工神經網絡。但到了 90 年中末之后貝葉斯統計模型更加流行。
1993-1994 年左右還在加拿大滑鐵盧大學當教授的時候,我和我的一位博士生合作了一篇非常漂亮的論文,當把線性的項加到非線性的項之后,可以增強神經網絡的記憶能力。并且我做了很多數學上比較嚴謹的分析為何記憶能力可以增強。那時電腦的計算能力不夠,模型做的很簡單,但這是一套完整的系統,但當把這個結果真正用在語音識別上時,卻還是沒有大大超過隱馬爾科夫模型的方法。
那時,我為這個博士生論文答辯找的 External Examiner 就是 Geoffrey Hinton,他過來后看到我們的研究就說神經網絡真是太難了。但這個博士生還是拿到了博士學位。因為這次的研究結果,我就很長之后不做神經網絡研究了,開始完全轉向貝葉斯統計方法和生成模型 (Generative Models)。
現在大家因為深度學習對 Hinton 和神經網絡比較關注,但實際上他的很多方法也是基于生成模型,比如說深度信念網絡(DBN),它并不像傳統的神經網絡,而是一種從上到下的生成模型。最頂上是兩層雙向(從上到下和從下到上)的生成模型,然后完全從上到下生成數據。最底層代表了數據向量 (data vectors)。
之后我在微軟研究語音識別。在有效的深層神經網絡學習方法發明之前,我用貝葉斯網絡方法把隱馬爾科夫模型(頂層)和 人類語音生成模型相結合并設計了很多層次。多層次是必須的,因為目的是要把重要的物理現象模擬出來。隱馬爾科夫模型只是模擬了對大腦對聲音的編碼這個行為,但整個過程中還包括肌肉運動控制、口腔內聲道運動等環節,最后通過聲學轉化才能變成語音,這就需要許多層,包括對噪音環境的模擬。但這種多層結構不見得就一定是神經網絡,用深層生成模型能更自然地實現。
當時(2002-2006)我在微軟領導一支小團隊在這方面做了很多研究工作。那時相對比較有效的理論就是貝葉斯網絡與相應的方法。但關鍵在于,如果層數很多,并且在動態過程中進行語音識別時,它的學習和推斷過程很難駕馭。就是說,增加層數后帶來的計算復雜度呈指數級增長。我們發明了很多方法來近似指數級增長的計算。近似之后結果還不錯,但是比精心設計和調制的隱馬爾科夫模型在準確率上沒有非常大的進步,但計算量卻大得非常多。
后來我就看到了 Hinton 2006 年關于深度信念網絡的論文(注:《A fast learning algorithm for deep belief nets 》)。當時我就很奇怪,他的這個生成模型也是很多層,為何沒有出現這些問題?2009 年,我請 Hinton 來微軟討論這個問題,就發現深度信念網絡比較容易的原因是它不涉及動態。我們就把嚴謹的動態模型去掉,但把時域上的向量數加大來近似嚴謹的動態模型,最后的簡化模型給出的結果還不錯。但另外一個問題是,即使用了簡化的動態模型,有很多層的深度生成學習仍然需要很大計算量。于是我們就想到了下一個巧妙的方法:把生成模型倒轉方向 --- 在語音識別中我們有許多打好標簽的數據,我們就可以使用自下而上的神經網絡而不是自上而下的生成模型。 這實際上就成為深度神經網絡與隱馬爾科夫模型結合的雛形。最后的實驗結果就讓人滿意了,而且學習的過程也更加可控。
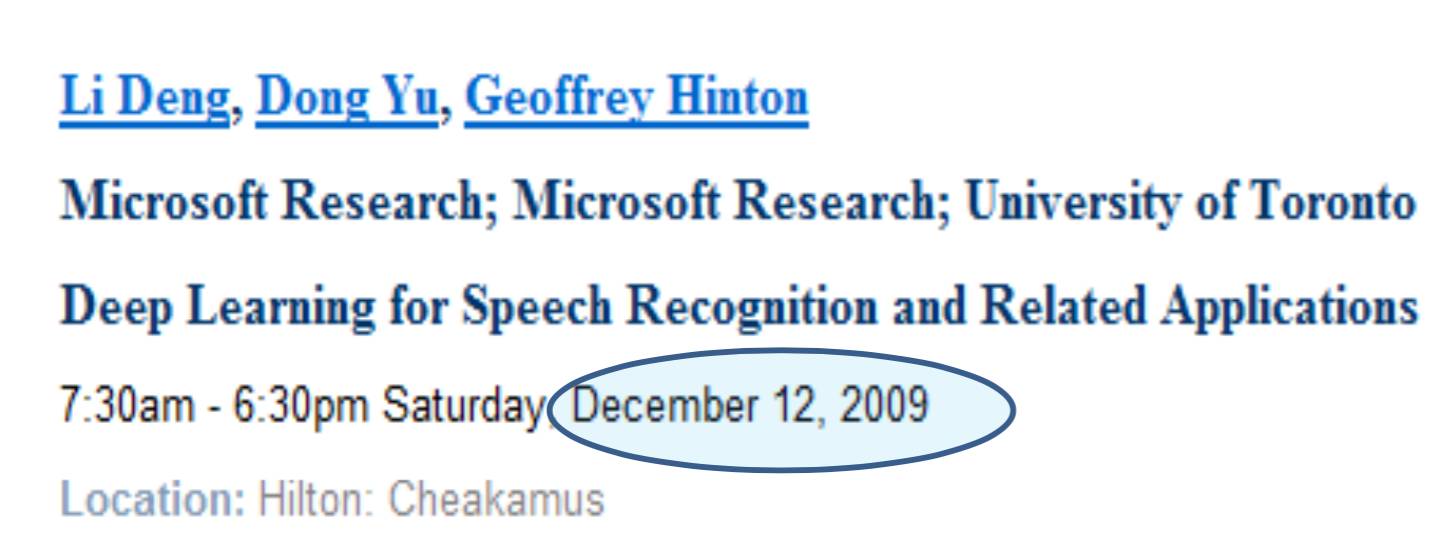 鄧力與 Geoffrey Hinton 合辦的 NIPS Workshop 《Deep Learning for Speech Recognition and Related Applications》,首次將深度學習用于語音識別。圖片來源:鄧力演講 PPT。
鄧力與 Geoffrey Hinton 合辦的 NIPS Workshop 《Deep Learning for Speech Recognition and Related Applications》,首次將深度學習用于語音識別。圖片來源:鄧力演講 PPT。
這是當時我和 Hinton 合作研究的一部分內容,把隱馬爾科夫模型和深度神經網絡結合起來,并取得了比較好的初步表現。但是所用的一系列近似產生了其他問題。比如,發音系統的運動是產生語音的一個因果機制(causal mechanism),但神經網絡無法模擬這種關系。 所以這種深度神經網絡失去了大部分的解析性。這在語音識別應用上問題不算太嚴重。但在我現在領導的很多其他更重要的應用上, 問題就嚴重得多。所以我們在做多方面很深入的研究來推進改善現有的深度學習方法。
這種方法整合和創新的思路同樣可以用于無監督學習。我在這方面想了很多,與團隊成員一起工作,經驗也積累了不少。
機器之心: 您和 Hinton 合作了很長時間,他對您有什么啟發嗎?
鄧力:他非常好,我從他身上學到了非常多東西。他對科學充滿了激情,而且有著非常好的洞察力,特別對類腦算法的研究非常深入。記得上次同他討論的整個小時談的都是類腦算法。過去在和他合作的過程中我收獲很大,也希望將來能有機會和他繼續合作。
 鄧力和 Geoffrey Hinton,圖片來源:微軟研究院。
鄧力和 Geoffrey Hinton,圖片來源:微軟研究院。
三、對人工智能研究現狀和未來進展的看法
將來人工智能的成功一定是不同種類方法的整合,就像人一樣,擁有各種思維方法的完整系統,應該很自然的把神經網絡方法、貝葉斯理論方法, 符號式邏輯推理等其他理論方法整合在一起。
機器之心:從 NIPS 2015 來看,不同神經網絡之間的模塊化組合越來越多,您如何看待這種趨勢?
鄧力:現在人工智能之所以這么成功,就是因為模塊化,可以把不同成功的工具和方法整合在一起。比如在復雜的神經網絡里,以前大家沒有為訓練用的自動求導工具,要花大量時間做求導和程序開發及調試工作。有了這些模型組合和工具之后,您只需要訓練輸入數據,訓練結果就出來了,訓練也就完成了,省了很多工程量。所以這種趨勢對以深度神經網絡為主的人工智能快速發展非常有利。
機器之心:目前序列映射學習(sequence to sequence learning)的效果非常好,它在應用中還有哪些局限嗎?
鄧力:所謂 sequence to sequence,最早(一年半前)Google Brain 研究人員用在機器翻譯時是基于用一個「thought vector」來對整個輸入句子進行編碼。 但是它的記憶(memory)不夠好,后來加上了注意模型(attention model)來彌補記憶不足的問題,所以現在的機器翻譯用了注意模型之后已經比之前序列映射學習有了很大提升。我覺得這個方法還不錯,但是更好的方法是把記憶能力進一步提升。總之,sequence to sequence 是一個很好的方向,而更好的方向是 structure to structure。
機器之心:您認為在深度學習研究中還面臨著哪些亟待解決的問題嗎?比如 Yann LeCun 和 Yoshua Bengio 就一直強調說,需要在無監督學習方面取得突破。
鄧力:我也在去年夏天就看到這個重要問題有解決的希望。目前我們團隊花了很多精力在做有自己特色的無監督學習,但這方面的研究確實比較難做。目前在我們團隊之外我看到大家的想法不少但還沒有很大的思想突破,我所看到的資料里都沒有實質性的進展。
把無監督學習做好是一個很大的挑戰,而我們獨特的的解決辦法依賴于四種知識源泉。1)沒有標簽也不要緊,因為人類學習也不見得每次都有標簽。在沒有標簽的情況下你就要利用知識,知識應該很容易并幾乎不花錢得到,因為很多知識都是現成的,比如說標簽的統計特性。現在的機器學習、語音識別和圖像描述都可以使用這種統計特性,從取之不盡、用之不竭的互聯網和其他大數據中抽取出語言序列的統計特性。這就是說,我們是把輸出部分的結構挖掘出來并巧妙地利用它。2)把輸入數據的統計結構模擬出來并加以利用。3)模擬并利用從輸出(標簽)到輸入的關系,這個任務是傳統神經網絡很難做的了,只能依靠與深度生成模型(Deep Generative Modeling)。4)從輸入到輸出的關系,這個任務是目前神經網絡非常擅長的。如果把四種知識源泉全部巧妙地用上,就有可能解決無監督學習問題。所以,要解決無監督學習問題,現有的深度神經網絡方法是不夠的。
 深度無監督學習的要點,來源:鄧力演講 PPT。
深度無監督學習的要點,來源:鄧力演講 PPT。
機器之心:雖然目前深度學習越來越強大,但之前傳統的線性方法和深度學習之間是否也應該是相互補充的關系?
鄧力:相對簡單的問題可以用線性方法,比較復雜的問題就要用深度學習非線性方法。但有時線性方法也會幫助幫助非線性深度學習方法。比如我開始給你講的我同我的博士生 1994 年發表在《Neural Networks》上的論文——將線性項加入非線性項會提高原先非線性時間序列的時序記憶能力(temporal correlation structure)并給出嚴謹的數學分析。 又比如我的同事們近期所研究的 深度殘差網絡(deep residual networks) 多層結構,還有我和團隊在 2011-2013 期間所研究的 deep stacking networks 與 deep kernel networks 都是通過線性方法和非線性方法結合在一起的。所以線性方法還是很有用的,應該成為深度學習的一部分。
機器之心:有研究者稱目前的深度學習需要的數據量太大。紐約大學的 Gary Marcus 一直在批評深度學習,他認為應該像嬰兒一樣通過極少數案例就能完成學習。另外,根據 Brenden Lake 等人在《Science》發表的論文《Human-level concept learning through probabilistic program induction》,使用貝葉斯程序學習的方法讓機器很快就能學會陌生字符,解決了特定任務下「one shot」學習的問題。深度學習是不是也應該和其他方法結合起來,來應對不同的數據量?
鄧力:我同意,如果是少量數據的話,神經網絡不見得是最好的。將來人工智能的成功一定是把不同方法的整合,就像人一樣,人的不同的學習方法也很難明顯的區分開來,這是一個完整的系統,應該很自然的把神經網絡理論、貝葉斯方法等其他理論整合在一起,這樣就和人類大腦有點像了。
 人工智能未來研究的挑戰,來源:鄧力演講 PPT。
人工智能未來研究的挑戰,來源:鄧力演講 PPT。
這個實現之后,遇到大量數據就使用從下到上的神經網絡方法,遇到少量數據就使用從上到下的生成模型,但最好的是將兩個過程循環使用。就像人腦一樣,白天是從下到上,看到東西聽到聲音產生感覺;晚上從上到下,做夢生成,不好的東西丟掉,好的東西儲存進入記憶。人類不斷重復這個醒與睡和睡與醒的過程,而我們的訓練方法也應該這樣,又有感知,又有生成。目前的深度神經網絡還比較簡單,信息主體上是從下到上,還無法做到以上那種循環。
我讀過 Brenden Lake 等人在《Science》發表的這篇很強的論文。他們的實驗顯示,單單靠從下到上的神經網絡是無法完成類腦的人工智能的。
機器之心:接下來人工智能的研究是否要從神經認知科學領域獲得越來越多的靈感?
鄧力:我是很贊成這個,但要非常小心。Gary Marcus 屬于人工智能和認知科學流派中的符號主義,符號主義可以做推理,但比較難做學習。我和團隊同一些大學教授合作,現在的很大一部分工作是如何將符號處理的推理跟深度神經網絡整合在一起,使得符號處理可以用深度學習的方法來完成。這個研究課題就是從認知科學領域的核心問題啟發出來的。
從整個人工智能體系的方法和認知科學來看,符號處理和推理屬于一派(Symbolists);神經網絡屬于聯接主義(Connectionists);第三個是基于統計學的貝葉斯方法(Bayesians);第四種是演化理論(Evolutionaries),但這個實在太慢了,離產業比較遠。第五種叫做類比學習(Analogizer),但類比學習有自己的局限性,數據大了之后無法規模化,但是在某些情況下還是可以用。
我覺得到最后這些方法應該全部整合在一起,生成一個非常漂亮、統一的理論,不管遇到各種數據量、各種場合都可以處理。但是從研究來看,不可能五個一起做,我們是兩三個整合一起。這個是基礎研究,研究到一定程度如果好用,我們再把它應用。
機器之心:之前的自然語言處理、語音識別會基于規則、語法等語言學理論,現在的深度學習研究者是如何看待 Norm Chomsky 語言理論的?
鄧力:我認為 Chomsky 語言學理論的一部分還是有用的。為什么呢?像剛才講的那個貝葉斯程序學習的「one shot leanrning」實際上就和 Chomsky 的理論有點像。所以這個是不能丟掉的,尤其是要做無監督學習的話。當數據少甚至沒數據或他們的標簽的話,我們就需要知識庫。當您想要把標簽丟掉來做學習(這會節省巨大資源所以很有實用價值),這些知識庫應該都要加進來。至于如何添加,也不是按照以前的方法,而是將其作為一種知識源加進去。我覺得完全丟掉這樣一個如此重要的研究成果太可惜了,Chomsky 語言學確實有它的道理,但最大的局限性在于它不重視學習而把語言結構知識歸于天賦(innate)。 因此,如果將 Chomsky 理論和深度學習進行整合的話會最好。
機器之心:DeepMind 創始人 Hassabis 曾表示,他們所研究的深度增強學習是要實現一種通用的解決方案,您在演講中提到增強學習其實解決的是決策最優化的問題,那它將來的應用是不是非常廣泛?
鄧力:這兩者是一致的。決策最優化的問題就是要解決采取什么樣的方案才能取得長期的最佳利益。這是非常通用的。這個問題也可以看成用現有的觀察數據(狀態變量)來「推測」什么是現時的最佳行動。這里并沒有在有監督學習中提供的「標簽」信號, 而且需要做有監督學習中不需要的探索(exploration)。
以前的增強學習在實際應用上無法很好的工作,是因為狀態空間 (state space) 很大,只能做一些小規模的基礎研究,太大的狀態空間會帶來更多的指數型增長的參數,就無法進行學習。而近期由 DeepMind 帶來的深度增強學習的突破在于把很大的狀態空間用深度神經網絡表達出來,而不是像傳統方法一樣把幾乎無限大的所有空間模擬出來。比如 DeepMind 研究的 Atari 游戲,狀態空間極端的大。在 DeepMind 引入深度神經網絡之前,傳統的增強學習方法無法處理。以前也有過用線性方法將狀態空間成一個低維向量,但這樣太粗淺。深度增強學習把這種機制變成可生成,而且很大,在這種情況下就可以用深度神經網絡計算出來的向量把很大空間上的信息吸收進來,而且我們有了很強的學習方法。因此,現在增強學習的成功就是深度學習成功的強有力的證明。
講到決策最優化和深度增強學習, 我的團隊現在還有一個研究就是基于自然語言的人機對話。以前的對話方法很難做成,但我認為深度增強學習會使得人機對話研究有所突破。
四、給人工智能從業者的建議
如果你想要做很實際的應用,就要看準現在已經很成功的方法;如果你想去推動這個領域的發展,做一些非常前沿的研究,那在機器學習和人工智能的基本功方面就要有深厚積累。
機器之心:您在人工智能和語音識別領域有著豐富的研究經驗,取得了令人矚目的成績,微軟研究院也非常注重人工智能基礎研究,希望推動行業發展。在人工智能研究方面,您能否給國內的研究者提供一些建議?
鄧力:據我所知,國內有很多公司和研究機構在這方面已經做的很好了,比如科大訊飛、百度、思必馳和出門問問等在語音方面就做的非常好。
微軟有著比較好的研究條件,而且作為一家大公司想做比較前沿的技術研究,以影響整個科技發展的潮流。我所主持的工作一大部分是在做這方面研究,就是多次提到的把不同種類的人工智能方法整合起來并從中開拓創新領域。所以從這個角度來講,我感覺這方面的基礎研究一定要做好,這樣才能夠影響人工智能的發展,甚至是科技的發展。國內在這方面好像缺少了一點。
機器之心:他們之所以缺少這些東西,是因為沒有像微軟、谷歌這么好的硬件條件?還是說在研究的文化和理念上有一些缺失?
鄧力:我覺得更多的在于理念上可能不太一樣,但現在中國顯然比以前好多了,因為有很多從國外回來的研究人員,他們將這種理念帶回了國內,所以中國在這方面的觀念正在改變。
13 年前有本書叫《成長——微軟小子的教育》。 當時李開復安排我跟作者凌志軍會談,志軍問了我一模一樣的問題,我的回答是中美之間在教育和思想方式有很大區別。我現在已經改變了這一點,從教育上講,中國確實不比美國差。中科大、清華北大這些學生的成績非常好。我當時從科大畢業去美國讀研究院,我的導師認為我本科畢業時掌握的知識是美國碩士才可以學到的。但我覺得可能還是缺乏一些靈感和想象力。
我舉個例子,這個例子好像在凌志軍的書上也出現過。在一次 IEEE-ICASSP 會議上,國內一位語音專家問我,為什么你們北美教授寫的論文都是很新的東西?那是 20 年前,每次會議的論文集都特別厚,我們的方法是在開會時記錄一些重要的東西,然后經過思考去做一些新的東西,而這位中國教授則是把這 1000 多頁的資料帶回國,每天打太極拳打累了就看幾頁,一年 365 天剛好看完。當時我就想,難怪在科研上很難創新,把時間都花在了去年的研究成果上。這可能和中國的文化有關系——一定要把現有的東西學習透,然后才去做創新。但有時不需要這樣,你要把不重要的東西丟掉,把核心信息提取出來,這樣才能更好的創新。不然你連發現哪些是前沿研究的時間都沒有。我現在通過媒體獲取信息也是這樣,不重要的東西要立刻忽略掉。所以判斷力很重要。
做科學研究一定要找到最正確的方法。比如剛才提到的無監督學習的重要性,我很早就知道無監督學習很重要,但找到解決的辦法是很困難的。你要不斷嘗試,從失敗中吸取教訓,在這個過程中一定要看準大的目標,把一些沒用的過濾掉。
機器之心:現在有越來越多的人工智能工具開源,而國內的公司又比較注重商業,缺乏做底層創新或基礎研究的文化。那開源是否會助長「拿來主義」,使他們把更多的精力放在商業應用上,而更加忽視了基礎研究?
鄧力:我的意思正好相反。開源并不是說你拿來之后就可以直接用,有開源工具是會使你創新更快。之前我要設計一些算法,我都不敢把神經網絡架構和算法設計的太復雜,因為實習學生的實習時間通常就 3 個月,架構和算法太復雜就可能會在有限期內完成不了指定的項目。而現在我就敢把神經網絡架構和算法做的很復雜了,因為有了這些開源工具,我們把幾個模塊搭好,學生就不用一個個去推導了,可以直接獲取結果。所以,并不是大家都依賴開源而不去思考新的東西,而是開源以后會讓你更有膽量去做更復雜的模型。再拿無監督學習舉例,開源大大加快了我帶領團隊的研究速度。所以,開源確確實實對深度學習的進展起了一個非常大的推動作用。越多開源越好,因為開源的主要好處是大家集體貢獻,形成一種良好的生態圈, 并同時推動更快速地實驗檢驗人工智能方法的有效性。
機器之心:微軟在人工智能技術應用上也做到非常出色,包括實時翻譯、圖像識別等工具,在人工智能技術應用方面,您有沒有一些心得或者建議給到國內的人工智能公司?
鄧力:實際上我們微軟在人工智能技術應用上的很多重大進展尚未對外公布。至于心得或者建議, 我想說的是做人工智能研究和應用的技能有幾個層次。最底層的技能就是把各種方法弄懂,知道它們各自的局限性。第二層的技能就是把各種工具用熟練,看到問題后馬上匹配相應工具,這樣就可以把模型做大,解決更難的問題。第三層技能是,要知道在具體領域中哪些方法可以用,哪些方法不可以用。比如說,過去幾年內我做了大約20 方面的深度學習和人工智能應用,然后一邊看應用一邊看數據,理解數據的性質,理解數據多還是少,是否有標簽,標簽是否干凈可靠,要弄清楚這些因素如何影響深度學習方法的有效性,這是需要長時間積累的。因為目前深度學習還沒有一個非常漂亮的理論,所以還無法非常明確的解釋什么情況下可以得到什么結果。所以我認為,如果想要做很實際的應用,就要看準現在已經很成功的方法;如果你想去推動這個領域的發展,做一些非常前沿的研究,那在機器學習和人工智能的基本功方面就要有深厚積累,只有這樣你才能知道不同方法的優勢和局限。
機器之心:去年發生了一個事情,機器在解釋圖片時把一對黑人夫婦標記成了大猩猩,這種問題對于我們做后續研究會帶來哪些啟示嗎?
鄧力:我覺得這個問題暴露出了人工智能的一些缺點,這就像 AlphaGo 輸掉一局一樣,你經歷過這些錯誤之后就學會了這種方法的局限性, 然后開拓新方法新理論。以后公司對此要格外小心,并且我們要從這類錯誤中吸取教訓,這樣人工智能就會更少的犯這種錯誤,這種反復會使人工智能有新的提升和突破。其實這種政治性的錯誤還是很容易避免的---只要把一些敏感詞除掉。
機器之心:您在日常研究和學習過程中,有哪些獲取信息和閱讀的技巧和方法嗎?
鄧力:我主要是在 Facebook、Google+ 上關注一些優秀的研究者,包括 Yann LeCun、Geoffrey Hinton 和 Yoshua Bengio 等,然后設置一些信息推送。NIPS,ICML,JMLR,arXiv 上都有很新很好的工作進展,偶爾 Science 和 Nature 也會有。 另外,也會通過微信閱讀一些中文內容,希望有更多的機會讀機器之心的相關中文內容。
致 謝
采訪稿完成后,鄧力研究員在百忙之中拿出了幾個小時的時間,非常嚴謹的對涉及人工智能理論和技術細節的內容做了確認和補充,以保證讀者獲取更加準確和翔實的知識。在此,對鄧力研究員表示由衷感謝!同時,也感謝阿爾法公社邀請機器之心參加此次會議,并積極促成了本次專訪。
本文由機器之心原創
| 歡迎光臨 (http://m.raoushi.com/bbs/) |
Powered by Discuz! X3.1 |